
Ich habe mein Englisch sprachiges Wiki unter wiki.natenom.com schon Anfang diesen Jahres in den Ruhestand geschickt. Alle Inhalte waren jedoch weiterhin verfügbar bzw. viele Seiten wurden in mein Wiki unter wiki.natenom.de verschoben und entsprechend mit 301-Weiterleitungen versehen.
Doch obwohl ich im Wiki nichts mehr gemacht hatte, musste ich mich doch immer wieder um Sicherheitsupdates für MediaWiki kümmern, auf dem dieses Wiki basiert.
Deshalb wollte ich schon mehrmals dieses Wiki mit Hilfe von wget herunterladen und dann als statische Version nur mit HTML-Dateien wieder hosten. Bei meinen letzten beiden Versuchen, das zu tun, bin ich immer an etwas gescheitert. Heute habe ich es endlich geschafft nach mehreren Stunden Arbeit und daher soll der Ablauf hier hinterlegt sein.
Ausgangspunkt war dieser Blogbeitrag. Jedoch musste ich den Aufruf für mein Wiki etwas anpassen und noch weitere Arbeiten erledigen.
Weiterleitungen temporär deaktivieren
Wichtig bezüglich meines Wikis ist hier der Punkt, dass ich früher bereits viele Seiten manuell in mein Dokuwiki verschoben und auch entsprechende 301-Weiterleitungen gesetzt habe. Deshalb habe ich diese Weiterleitungen temporär entfernt und dann erst die Seite heruntergeladen.
Man könnte sie auch aktiv lassen und stattdessen noch bei wget diesen Parameter nutzen:
--max-redirect 0
Damit würden Weiterleitungen generell ignoriert werden. Mir war es aber wichtig, alle Seiten des Wikis im Archiv zu haben.
wget
Los gehts mit wget:
wget --recursive --domains=wiki.natenom.com --html-extension --page-requisites --convert-links --no-parent -R "*action=*" -R "*printable=*" -R "*oldid=*" -R "*title=Talk:*" -R "*limit=*" "https://wiki.natenom.de/w/Main_Page"
Erklärung der Parameter:
--recursive
Das ganze Wiki soll heruntergeladen werden.
--domains=wiki.natenom.com
Es sollen nur URLs von der Domain des Wikis heruntergeladen werden.
--html-extension
Alle URLs werden in Dateien mit .html am Ende lokal abgespeichert, aus „https://wiki.natenom.de/w/Blaseite“ wird w/Blaseite.html
--convert-links
Alle internen Links werden so konvertiert, dass auf die jeweiligen relativen .html-Dateien verlinkt wird, statt auf Originalwebseite.
-R ...
Überspringt URLs, die bestimmte Strings enthalten, z. B. den Namensraum Talk und weitere.
Wenn es Probleme gibt und eine Meldung in der Form no follow attribute found, dann benötigt man zusätzlich noch diesen Parameter:
-erobots=off
Ein Archiv mit der ganzen Webseite
Nach dem Herunterladen des Wikis gibt es im aktuellen Verzeichnis ein neues Verzeichnis mit dem Namen „wiki.natenom.com“.
Dieses wird gepackt und dann auf den Server hochgeladen und ersetzt in Zukunft die dynamische Variante des Wikis.
Für mein Wiki ist das komplette Archiv gerade mal ~60MiB groß.
Weiterleitungen einrichten, damit Links von draußen weiterhin funktionieren
wget hat im erstellen Archiv bereits alle heruntergeladenen URLs in Dateien mit der Endung .html umbenannt und alle vorhandenen Wiki-internen Verlinkungen angepasst. D. h. im fertigen, statischen Wiki enden alle URLs (außer Bilder) auf „.html“.
Wenn jedoch jemand von „außen“ über einen Link auf mein Wiki kommt, würde er ohne die Endung .html keine URL mehr abrufen können, daher muss man sich selbst darum kümmern, dass solche URLs weitergeleitet werden.
Dafür benötigt man eine RewriteRule:
Options +FollowSymlinks
RewriteEngine On RewriteBase / RewriteCond %{REQUEST_URI} !.html$ RewriteRule w/(.*) w/$1.html [R=302,L]
Da es unterhalb von /w/ nur Seiten gibt und keine Grafiken, gibt es auch keine Probleme, dass versehentlich Bilder nach .html umgeleitet werden.
Alle anderen RewriteRules werden aus der alten Konfiguration gelöscht.
Für die anfangs erwähnten 301-Weiterleitungen bereits früher verschobener Inhalte musste ich jetzt noch die URLs anpassen, damit diese auf .html reagieren und diese entsprechend in die neue .htaccess-Datei des statischen Wikis übernehmen.
Z. B. wurde aus:
RedirectMatch permanent ^/w/Android$ https://wikiarchiv.natenom.de/en/android
dieses hier:
RedirectMatch permanent ^/w/Android\.html$ https://wikiarchiv.natenom.de/en/android
Startseite des Wikis verfügbar machen
Jetzt sollte man noch einrichten, dass man die Startseite des Wikis auch dann erhält, wenn man auf die Hauptseite aufruft. Dies erledigt man am besten per Weiterleitung, weil die Startseite sonst mehrfach existiert mit gleichem Content. Jedoch würden dann die relativen URLs nicht passen, weil das /w/ am Anfang fehlen würde.
Daher trägt man in die .htaccess noch ein:
RedirectMatch ^/$ /w/Main_Page.html
CSS verfügbar machen
cd /xxx/htdocs/
cp load.php?debug=false&lang=en&modules=ext.cite.styles%7Cmediawiki.legacy.commonPrint%2Cshared%7Cmediawiki.sectionAnchor%7Cmediawiki.skinning.interface%7Cskins.vector.styles&only=styles&skin=vector.css “load.php%3Fdebug=false&lang=en&modules=ext.cite.styles%257Cmediawiki.legacy.commonPrint%252Cshared%257Cmediawiki.sectionAnchor%257Cmediawiki.skinning.interface%257Cskins.vector.styles&only=styles&skin=vector.css”
Sitemaps
In meinem Fall musste auch noch das Verzeichnis mit den Sitemaps kopiert werden.
Was nicht funktioniert
Bis auf wenige Seiten sieht alles aus, wie es soll. Hier ist die Liste aller Seiten im Wiki, falls jemand etwas bestimmtes sucht. Die Suche selbst funktioniert natürlich nicht mehr, so wie auch alles andere, was dynamisch generiert wurde, wie z. B. der Namensraum Talk.
Die richtigen Seiten mit Inhalten sind aber alle verfügbar und das war mein Ziel.
Informieren
Für mögliche 404 Fehler im jetzt statischen Wiki habe ich ein eigenes ErrorDocument für den Webserver erstellt, das kurz die Situation erklärt, damit der Besucher weiss, wieso es viele URLs nicht mehr gibt.
Die Datei heißt 404.html und über diese Direktive kann man sie aktivieren:
ErrorDocument 404 /404.html
Navigiert man zu einer URL, die es nicht mehr gibt, dann sieht man das Folgende:
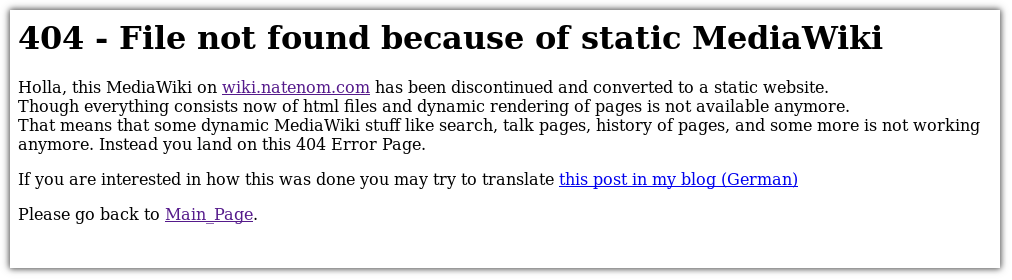
Das lässt sich auch in schön machen, aber mir reicht es aus.
Das wars dann mit MediaWiki
Jetzt muss ich mich nicht mehr um unregelmäßige Updates meines nicht weiter geführten Wikis auf MediaWiki Basis kümmern und muss mir auch keine Sorgen machen, dass es irgendwann eine Sicherheitslücke geben könnte.
Nochmal zur Klarstellung: MediaWiki ist eine tolle Software und man kann sehr viel damit machen. Aus meiner Sicht ist es für einen einzelnen Menschen administrativ aber zu komplex. Deshalb habe ich mich lieber wieder auf mein DokuWiki unter [wiki.natenom.de][2] konzentriert.
Perfekt :)
Kommentare
Bisher gibt es hier keine Kommentare.
Kommentar oder Anmerkung für diesen Blogbeitrag
Öffentlicher Kommentar per E-Mail: Hier klicken
Nicht öffentliche Anmerkung per E-Mail: Hier klicken
Sonstige Kontaktaufnahme: Kontakt